An interesting article appeared in the journal Science this past January, describing a new method of quantitative computational analysis by employing the vast and mostly hidden digitized library of Google Books for the sake of data gathering. The researchers called this analysis and (as they see it) the new field of study “culturomics.”
Basically, they worked with the smart people at Google to break down the body text and metadata of the entire Google Books library (5.2 million books) into single and multiple-word sets. This, according to google, is approximately 4% of every book ever published. After compiling these sets into enormous databases, they can then search simple terms and get a nice graph over time of trends in published books in the past 200 years (mostly in English…the foreign language data sets aren’t nearly as large). Lots of details and questions remain, obviously. What is the breakdown of this 4%? Is it an accurate representation of the whole? What is its statistical reliability? Etc. Unfortunately, those answers aren’t given (though they somewhat respond in their FAQ). But enough about the details…5 million books is a good amount, lets see how this relates to theology.
First, a simple test. Using the Google Labs version of this tool, I ran the keywords “Godself” and “God Himself” from 1960-2000. (Why not past 2000? See point 5.)
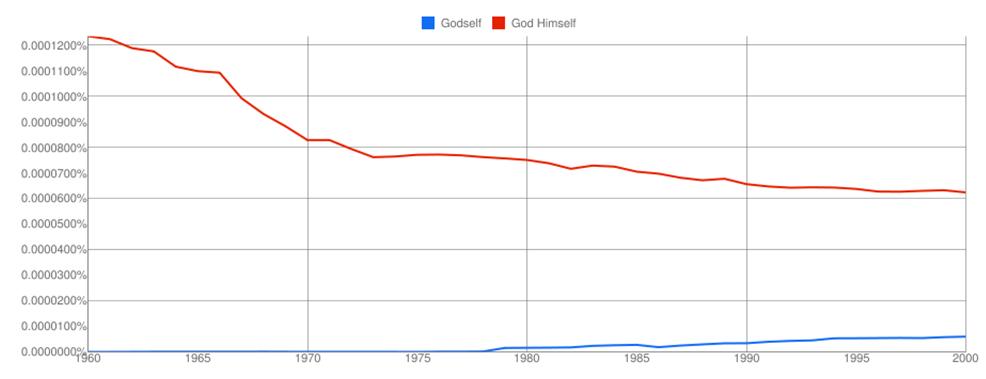
The percentage along the y axis is the overall percent of time this phrase appears in the entire Google Books corpus during that year. Thus, in 1960, the phrase “God Himself” existed in slightly more than one out of one million (~0.0001%) two-word phrases in the repository. By comparison, “Godself” practically did not exist (the Google labs tool doesn’t allow for exact numbers). All that aside, the comparison over time is quite interesting. By 2000, the phrase “God Himself” was less than half as popular, while “Godself” the steady decline of “God Himself” is easy to see, as is the slow rise of “Godself.” Taken on its own, the rise of “Godself” is even more apparent:
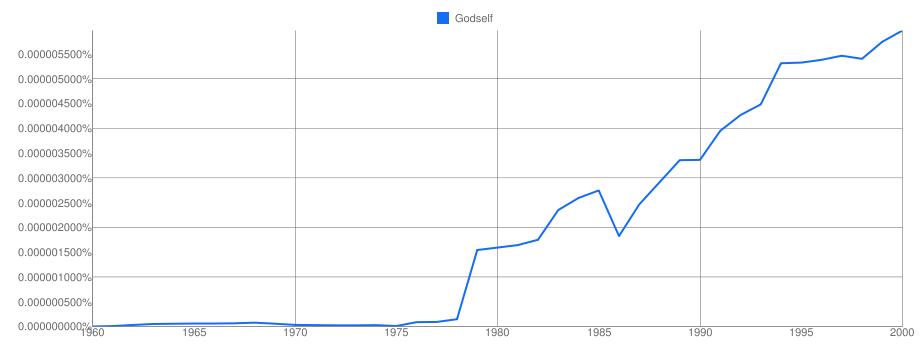
Quite interesting, and begs further questions. But lets leave those for later and do one more very interesting search.
For this search, I employed four search terms: “systematic theology” (blue), “liberation theology” (red), “Christian theology” (green), and “Catholic theology” (yellow).
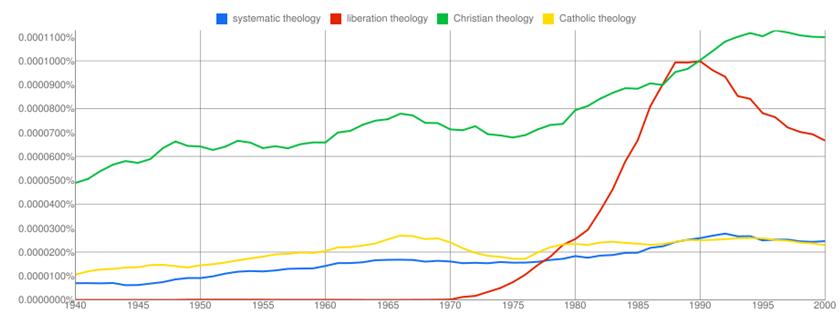
In this case, “Christian theology” was my control time, gently rising from 1940 until 2000. In comparison with “Christian theology,” one can see that the frequency of “systematic theology” falls pretty much in line with that of “Catholic theology,” both at approximately one-fifth the popularity of “Christian theology.” On the other hand, the meteoric rise of “liberation theology” is hard to miss. One cannot receive a degree in theology without brushing against the term one way or another, and many people could tell you how important or unimportant liberation theology is in the 21st century, but culturomics allows one to more quantitatively analyze its rise and fall.
While the rise of “Godself” is not surprising, the rise and seeming fall of “liberation theology” seems worthy of some analysis. First of all…is the data reliable? Can it be cross-checked anywhere?
Not precisely, but lets try Worldcat, the enormous internet library database, and a great way to have rare books brought right to your local library. Worldcat’s resources make Google books blush (apart from the full text stuff). Worldcat holds metadata for over 233 million bibliographic records which represent over 470 languages and 72,000 libraries (impressive, right?). No doubt repetitions exist, as do many non-books, but the numbers are still staggering compared to the 5 million books employed for culturomics.
So I went to Worldcat and performed a bunch of advanced keyword searches on “liberation theology” in a specific year to see if the general results matched those generated by culturomics. I then recorded the overall number of hits and the number of books specifically returned in that year. The result:
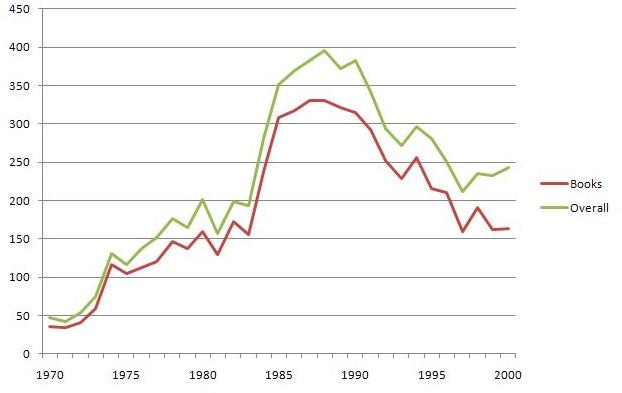
Pretty much the same! A steady rise in the 1970’s, a spike in the late 1980s, then a slow downturn until 2000. (Further research on Worldcat shows a levelling out after the year 2000 but we won’t go there since culturomics won’t).
In terms of historical analysis, the early 1970s saw the publications of Gutierrez, Cone, and Roberts (among others) which sparked the field of study. But why the spike in the late 1980’s?
To be honest, I’m not quite sure. My best guess is that the two CDF documents–in 1984 and 1986–which cautioned against aspects of liberation theology, authored by then-Cardinal Ratzinger, caused the theological world first to respond heavily (thus the late-1980s spike) and then to burst and settle.
Anyhow, this post isn’t so much about liberation theology as the ability to perform theological analysis using a very interesting technological tool. That is, by performing meta-analysis on the words surrounding and within texts without actually reading them. Heresy, perhaps? I don’t think so. There are simply too many books being published every year for anyone to adequately systematize everything! In 1988, in a well-known letter to the director of Vatican Observatory, John Paul II called for theologians to renew Aquinas’ quest to blend theology with the scientific theories of the day. Unfortunately for us, the science of the day encompasses a lot more than Aristotle ever dreamed of, and more volumes than one could possibly read in many lifetimes.
Clearly, however, such analysis does not replace a close reading of Gutierrez, Cone, or the Vatican documents mentioned. One cannot capture Gutierrez’ passion or Cone’s righteous anger and vision through meta-analysis. But one can, perhaps, chart where this passion and vision has led…and where it may go in the future.
I introduce these tools purely in hopes that others might both find these tools helpful, and so that we might find interesting ways of employing technology for the sake of theological thought in the future. The data exists and is growing…there must be some good way to make use of it! So, given the nature of the blog as a content-sharing and conversation-welcoming space, what do you think? Play around with Google’s culturomics tool or do some searches via Worldcat’s vast databases and let me know.
